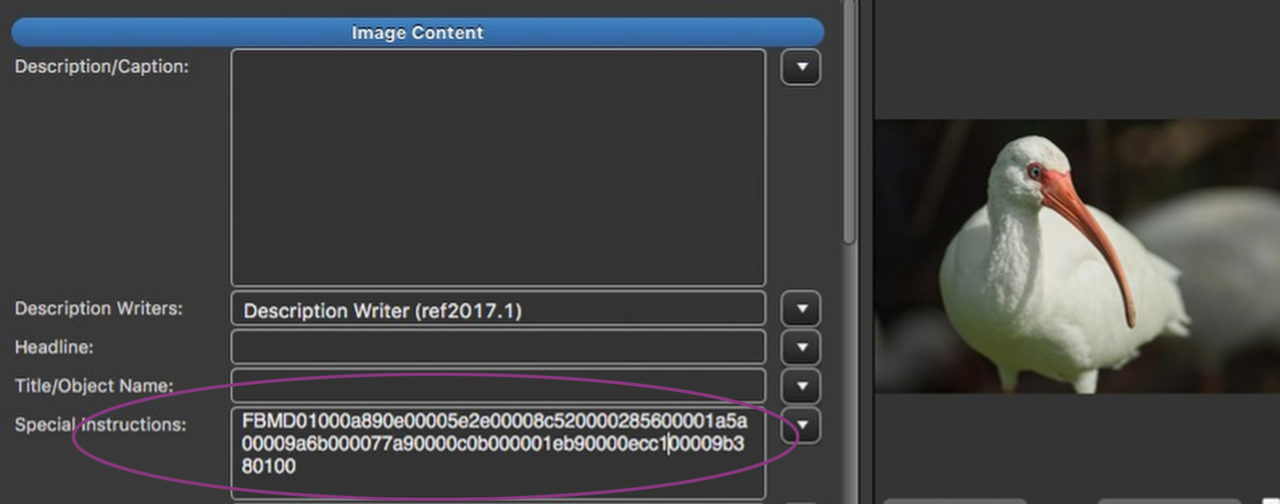
A nefarious metadata plot has been unearthed and news of it is streaking around the interwebs. An Australian law student named Edin Jusupovic was casually looking at photos downloaded from Facebook in a hex editor and tweeted about what he saw.
And from there, as they say, the rest was history. When last I looked, Jusupovic’s tweet had been retweeted 16,637 times, there were nearly 2,000 mostly clueless replies to his thread, and no less a journalistic standard-bearer than Forbes had weighed in: “Facebook Embeds 'Hidden Codes' To Track Who Sees And Shares Your Photos”, cried their headline.
How do you deal with photos that come to you with no metadata? If you watched my videos on preparing images for the web, you may have noticed that I said that "I tried to make the demo images look halfway professional.” Most of them had embedded metadata, in other words. You may have cried foul. “None of my [insert adjective] clients ever send me pictures that are labeled in any way!”
We can deal with that. We can slap on some metadata. To our optimizing for the web process, we’ll just add a step to apply the metadata that should have already been there. But we’ll only add seconds to the amount of time it takes. We’ll invest some think/plan/learn time now (again) and the physical process will go by in a blink.
Camera Bits has released version 6 of Photo Mechanic. Version 5 was released way back in 2012. According to Camera Bits’ Director of Marketing Nick Orlowski (sp?), there have been 43 updates to Photo Mechanic 5 during its six-year run. Many of those updates introduced new or refined functionality. Clearly, Camera Bits isn’t pestering their users for upgrade fees every time we turn around
Camera Bits has lowered the price of a full Photo Mechanic license by $11, to (USD) $123. The upgrade fee drops by a buck, to (USD) $89.
So, what’s new in this long-awaited new version of Photo Mechanic? I’ll go over some of the high points here.
Google has begun actively surfacing copyright metadata on Google Images. Now that the Copyright field itself is working, users can see all three of the IPTC fields Google promised a few weeks ago. What does this mean for website operators?
It means that, if you haven't already, you should make sure your site respects metadata on images.
If you haven’t already, you should, ah… encourage your content contributors to put their names on their work.
Did you set the time on your camera's clock back from Daylight Saving Time to Standard time this morning?
For those of us who live in the US, at two o'clock this morning time slipped back and we gained (temporarily) an hour of sleep.
Around lunchtime, I somehow remembered that I needed to change the time back on the clocks in my cameras. And I felt good about it in the way that you feel good about doing something that you know you should do religiously, but, well, you aren't quite as diligent as you should be.
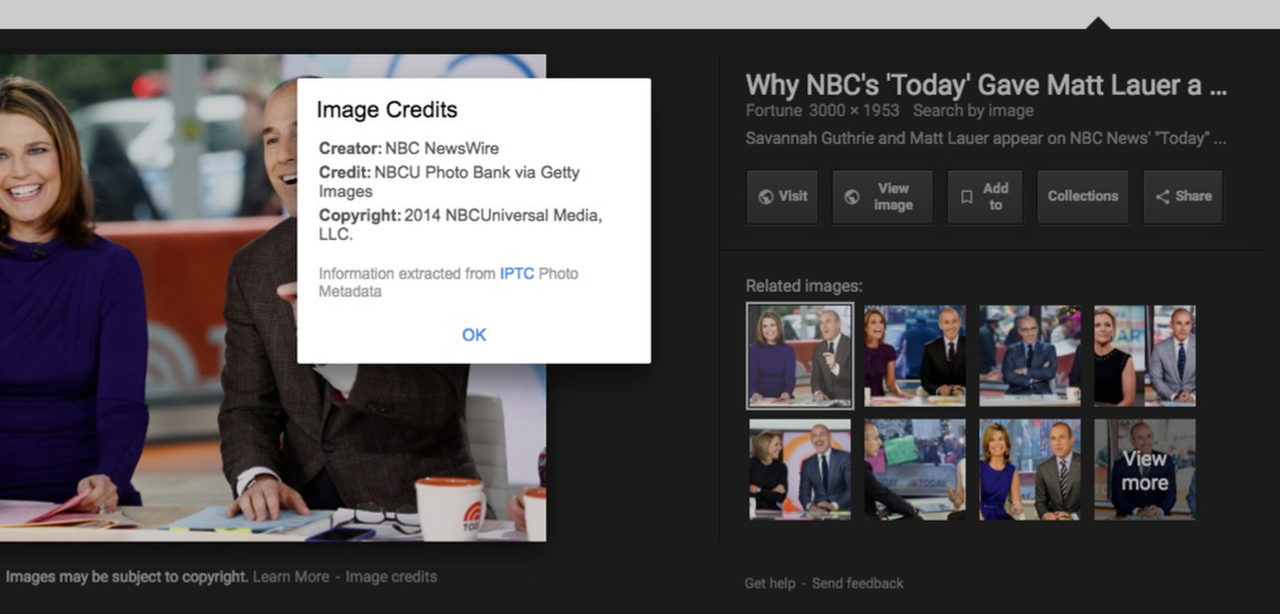
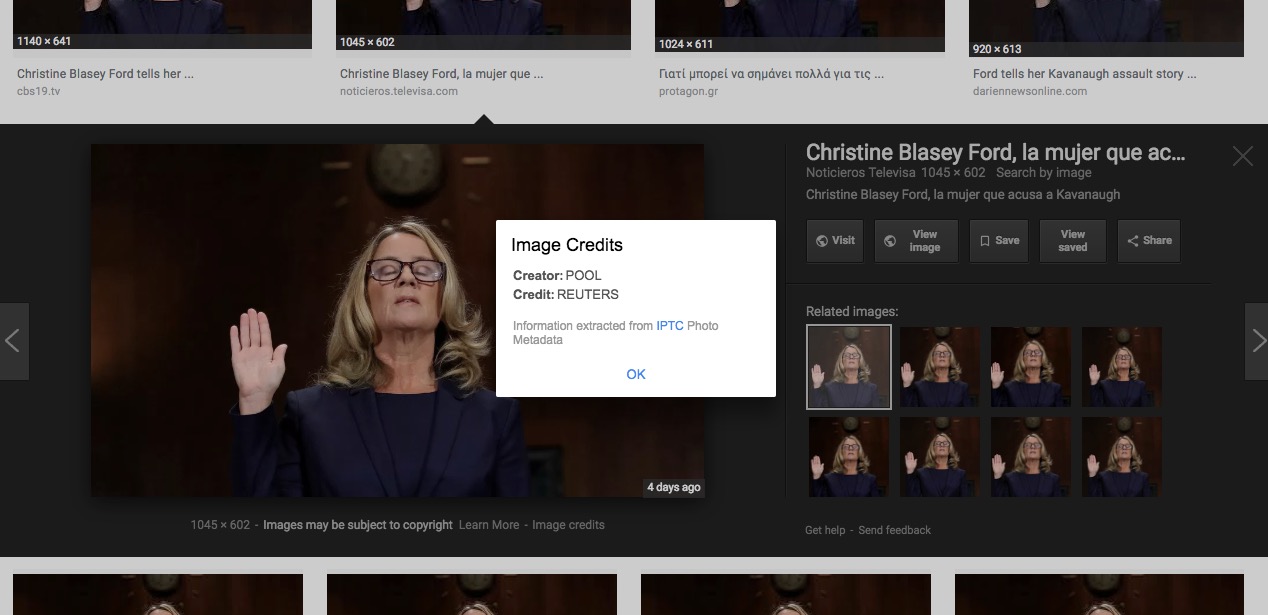
On September 27, Google announced that it would include limited support for IPTC metadata in Google Images. Next to the gratuitous “Images may be subject to copyright” disclaimer, users may now find a link for “Image Credits” if that metadata exists in the photo. They can now see for sure who owns the picture. That is, if, the relevant metadata exists in the image file.
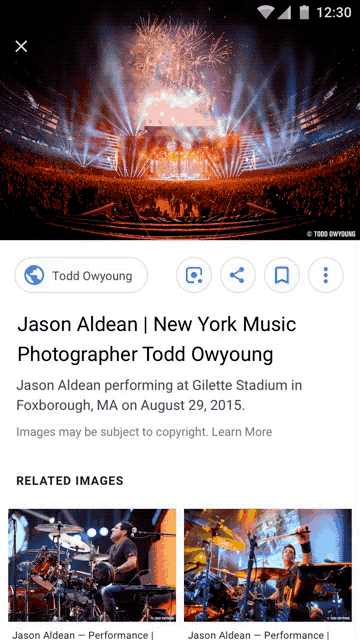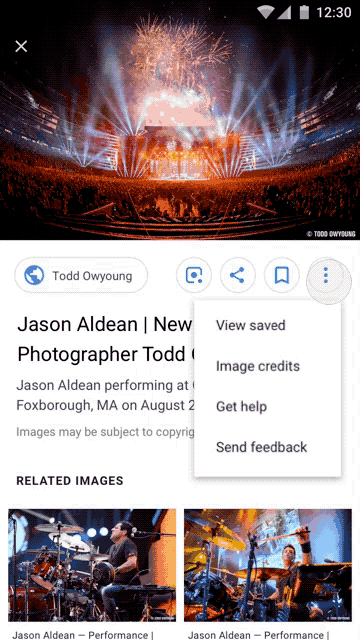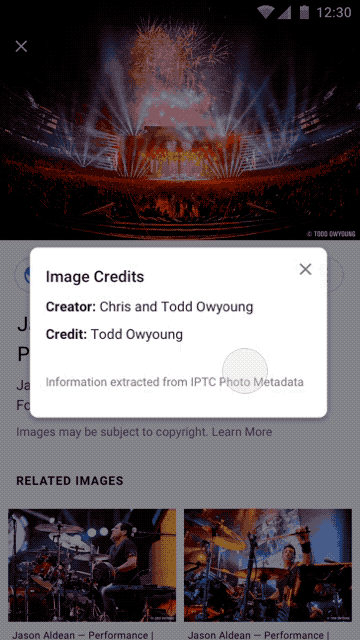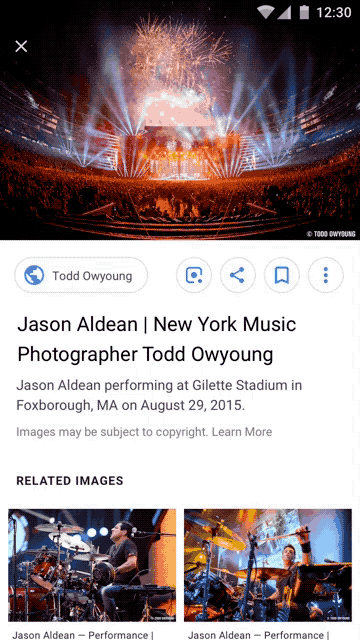
Google will now display to users, at least those who look, the contents of three copyright-related metadata fields - the IPTC Creator, Creditline, and Copyright fields. (The first two are operational now, the latter will be “in coming weeks.”)
This is a huge step forward for photographers. But “if” the metadata exists means we have to put it there.
Google used this GIF to illustrate their announcement. As we go to publication, we haven’t yet seen for ourselves the new capabilities.
Google Images will include copyright-related IPTC metadata
Google announced today that Google Image Search will support some IPTC metadata. In a blog post dated today, September 27, 2018, Google Images product manager Ashutosh Agarwal says that “Starting today, we’ve added Creator and Credit metadata whenever present to images on Google Images. … Over the coming weeks, we will also add Copyright Notice metadata.”
Google will read from the IPTC Creator, Creditline, and Copyright fields to expose the metadata information.
In the IPTC’s own press release, photo metadata guru Michael Steidl says, “Embedded IPTC photo metadata has an essential role for photos posted on a website. These fields easily show people searching for images who its creator and copyright owner is. We encourage all parties who post images on the web to fill in these IPTC fields.”
Damn right!
This is a huge win, folks. The IPTC, CEPIC (the Council of European Professional Informatics Societies, which is an IPTC member and collaborated in the effort) and Google have made a giant stride. The motto of this blog says that “metadata empowers honest people”, and that’s just what happened today. Google has used it’s enormous weight to push forward the role of metadata, enhance copyright protections, and by extension, promote honesty itself.
What’s new
Users, upon finding an image in a Google Image search will see a link for “Image Credits” on a photo’s search results page. Clicking through will reveal the metadata, first from the Creator and Creditline fields, and soon from the Copyright field as well. A further Google search should produce contact information for the copyright holder, from whom a license to use the image legally could be obtained.
What you need to know: The IPTC has published a Quick Guide for metadata for Google Images here.
Full faith and force
The key takeaway is that the “force of Google” has been imposed. Users with professional level skills know that copyright management information metadata can be read from an image on Google Images by simply downloading the image and looking at its metadata. Such users also understand that scarcely any images include any metadata, either because their creators didn’t bother to put it there, or because some website stripped it away.
And no one could help but appreciate the irony in Google’s “Images may be subject to copyright” disclaimer.
That changes today
As of now, photographers are on notice that if they wish their rights to be taken seriously, they need to sign their work in the metadata.
Website operators who want to please Google – which is to say all of us – will need to check to make sure their websites preserve embedded metadata. (See this post, and this one for information on making your site metadata-friendly.)
Designers and ordinary users will be able to see at a glance who owns a photo, assuming that person has labeled their work. (And there won’t be any excuse for not looking.)
Internet hosting providers now have more incentive to provide metadata-friendly default settings for their customers.
Quick copyright refresher
The creator of a work owns the copyright to the work, unless the creator is an employee whose job is the creation of copyrighted content, or the creator has explicitly transferred the copyright to another party. Thus, it follows that a copyright owner will be identified in the Creator or Creditline metadata fields. Later, when Google exposes the Copyright field, not only will it identify the copyright holder directly, but often will contain contact information, such as a telephone number or web address.)
SEO implications?
Google hasn’t said that it will consider IPTC metadata, and a website’s treatment of it, in calculating page rank. Let’s just say it wouldn’t surprise me. I’d be shocked if they don’t, frankly. If not now, soon. Google’s oft-stated mission is to surface the best quality, most relevant, content. The concept of “authority” has long been a critical means to that end. Respect for copyright and specificity in description of content certainly seem like markers of “authority” to me.
A mere hint that Google might value something usually causes a stampede of activity as SEO consultants spread the word to their clients, who, in this case, will surely pass on requests (or requirements) for metadata to their content providers.
It doesn’t hurt that sensible metadata is basically free Google “juice”. A reasonably full set of metadata adds only a millisecond or so to page load time. And setting a web server to be metadata-friendly doesn’t cost a darn thing.
Will Google look further into embedded metadata in the future? Will they, for example, compare the contents of a photo’s own caption with the caption on the web page and use the results to predict the relevance and freshness of the content? I sure would, in their place. As a human photo curator, that’s a strategy that I do use. Google is famously tight-lipped about their ranking algorithms. They’re also logical and smart. If Google’s support for embedded metadata makes embedded metadata more commonly available as a potential ranking factor, will they go ahead and use it? I’ll bet they will.
Technical stuff
Google will be reading metadata from the XMP and IIM data blocks, in that order. If XMP is present, it’s read. If not, the IIM will be read. That’s a sensible reading order, and in fact the one I usually recommend. No mention has been made by either Google or the IPTC of reading creator or copyright data from the Exif. That’s fine by me. I never thought that descriptive metadata belonged in the Exif block anyway.
Regular readers will know of the challenges and ambiguities of the Creditline field, and that I’m not too comfortable with using it in the way that is suggested by this development. Watch this space for new guidance as my views on this field are forced to evolve. (A summary of IPTC fields can be found here.)
“Starting today” tends to be an elastic concept for Google. As I write this post in the afternoon of September 27th, I haven’t yet been able to find a working example of the new functionality anywhere on Google Images. I have included the animated GIF Google used to illustrate its own post, but I have yet to see “Image Credits” in the flesh, not even on the image Google used in their own illustration. It may be a while before a Google Images search returns metadata for your images.
In their press release, the IPTC invites website owners and software developers to contact them for help implementing metadata support in products.
This blog is part of a pro bono effort in support of the benefits of good metadata. If you are a developer, a webmaster, or a content producer and you want help with metadata, you may reach out to me, as well. In most cases (and within reasonable limits) I provide help free of charge.
There is a metadata angle to this story. We’ll get to that. But first, let’s vent about the outrage. Outrages. Multiple outrages. There is so much that is so wrong here.
Our tale begins as the Post Office, best known in some circles for delivering letters, and in others for infringing sculptors' copyrights, begins production for a “Forever” stamp to be issued in late 2010. They wanted to do a Statue of Liberty stamp. They hired an image research consultant to scour stock agencies for a photo of the great statue.
Stock agencies?!!!!! Stock?! Why on earth would the Post Office use a stock photo of an iconic statue
In this post, we’ll talk mostly about the considerations and decisions that must be made to get ready for labeling our works under Creative Commons. Once you have a plan in place and some templates made, the actual workflow process is quick and easy.
A South African photographer is suing an agency of the South African government for copyright infringement. He is seeking a breath-taking 2.1 B-i-l-l-i-o-n Rand in damages. (I’m sorry. I can’t even type that number with a steady hand.) That’s north of $180,000,000 in US dollars.