Facebook preserves some of your metadata; Adds mysterious strings
A nefarious metadata plot has been unearthed and news of it is streaking around the interwebs. An Australian law student named Edin Jusupovic was casually looking at photos downloaded from Facebook in a hex editor and tweeted about what he saw.

And from there, as they say, the rest was history. When last I looked, Jusupovic’s tweet had been retweeted 16,637 times, there were nearly 2,000 mostly clueless replies to his thread, and no less a journalistic standard-bearer than Forbes had weighed in: “Facebook Embeds ‘Hidden Codes’ To Track Who Sees And Shares Your Photos”, cried their headline.
(Regular readers may note that we now know of two individuals geeky enough to casually peruse hex dumps of photos, the other being, well, me. Looking at a photo in a hex editor kind of reminds me of seeing an automobile through a microscope. Yes, the car is there, sure enough. But just glancing out the window and seeing the thing sitting on the driveway is a better way to see it.)
Hmmm. What’s this?
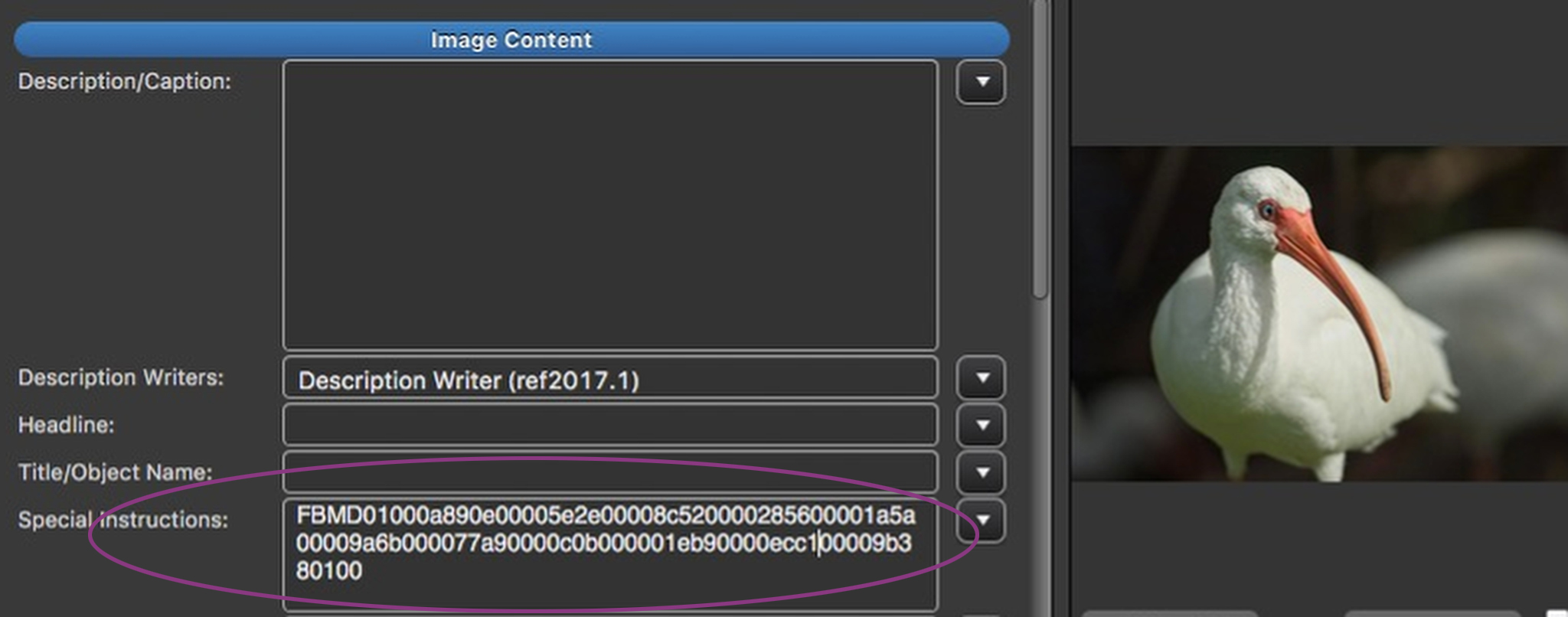
What Jusupovic came to “discover” was that Facebook had written a string of characters in the IPTC Special Instructions field on this, and every other as far as I know, photo on their site. What might be “structurally abnormal” about that, I haven’t a clue. But on with the story…. The irony here is that as far as metadata is concerned, Facebook is the least pernicious of the social media platforms. Facebook respects at least some of your copyright management metadata.
“The take from this is that they can potentially track photos outside of their own platform with a disturbing level of precision about who originally uploaded the photo (and much more).”, Jusupovic elaborated in a further tweet.
So, I presume we are to infer that Facebook is a bunch of shifty characters who do stuff behind our backs, and that metadata is very scary. The former is pretty obvious by now to anyone with an internet account and the latter is probably not a notion that readers of this blog especially support.
Let’s unravel this and see what we do and do not know. (Yes, a Pulp Fiction reference.)
UPDATE – The IPTC’s Metadata Working Group has weighed in on this story. Their post can be seen here: https://iptc.org/news/what-does-facebook-do-with-your-photo-metadata/ Note that David Rieck’s work, quoted in the IPTC article, indicates that Facebook does preserve creator and copyright information in the Exif data block. I missed this. Mea Culpa. Below, I give Facebook some credit for their treatment of Exif. This means they deserve a bit more credit still.
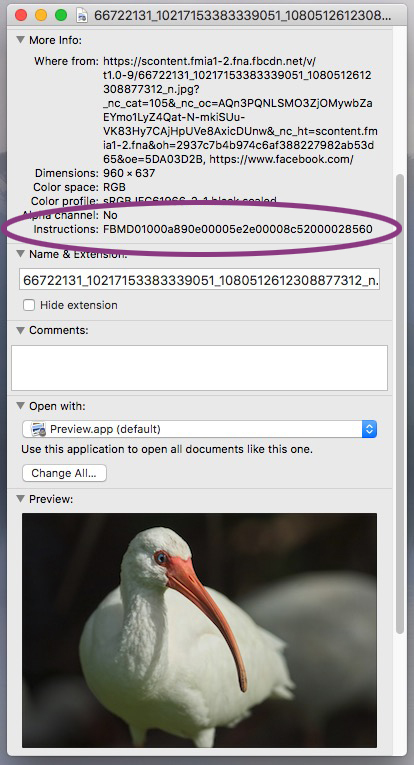
First off, while Jusupovic’s discovery came about whilst poring over the strings view window of his hex editor, which is looking rather more deeply into a photo than most of us might, we can also see the Special Instructions field by clicking on “Get Info” on a photo on a Mac desktop. Not exactly NSA-level sleuthing.
Hiding in plain sight?
That’s because IPTC metadata is a universal standard. It’s public. It’s where you put stuff that you want everybody to be able to see and read. To a greater or lesser extent, both popular consumer operating systems display IPTC metadata at a right-click. Any competent graphics program – about half of them, according to the IPTC – will display a fairly comprehensive view of IPTC fields. Those metadata fields would amount to an awfully in-your-face place for “Hidden Codes”. Whatever Facebook is doing, it’s doing publicly, which is oddly transparent for an outfit that everybody, including me, likes to demonize for underhanded dealings.
Then there is the matter of a “Shocking level of tracking..“ and, as Jusupovic went on to tweet, …“potentially track[ing] photos outside of their own platform with a disturbing level of precision about who originally uploaded the photo (and much more).” Before we look into what actually happens to photos that roundtrip through Facebook, let’s unpack this.
Let’s bear in mind that Facebook owns its database. In it, they have tucked away every little salacious detail about you that they think might ever be worth a penny or two. They know what you like and don’t like, who you like and don’t like, what your politics are, and, of course, they have a record of everything you’ve ever said on the platform. They have an archive of every image you’ve ever looked at, never mind uploaded.
So, a “Shocking level of tracking”? Absolutely. But does a public-facing ID number on a photograph significantly add to the damage? I rather doubt it. Let’s face it, on Facebook itself, the company knows everything about you and they have no reason to record any of that valuable data where you or a competitor might see it.
Off the reservation…
Off the Facebook platform is another story. Conceivably, someone could download a photo from Facebook and upload it to some other website. (That’s copyright infringement, by the way. Not that anyone except people who used to make a living at photography would care.) In such a case, Facebook could conceivably crawl the web and see that “their” picture had found its way off the reservation. If such a picture was to be re-uploaded back to Facebook, Facebook would be able to tell where it came from. And from whom. Right?
Sort of. Not really. As regular readers are all too sadly aware, the imaging libraries on most websites strip all metadata off photos. This blog constantly pleads for website operators to do the community-minded thing and configure their sites to honor metadata. But, despite my efforts, according to a study by Imatag, 85% of photos on the web carry no metadata at all, and 97% don’t identify their copyright owner.
If Facebook is trying to track photos off their site, this would be a lousy way to do it. Yes, given their scale, maybe they could glean some data about where photos that leave their site go generally. Er, check that. They can’t. The skewed data would indicate that photos stolen from Facebook always end up on websites that don’t strip metadata, so that won’t work. As a way to surveil individuals, this is a no-go.
Maybe another way
Steganography, embedding hidden data directly in an image’s pixels, would be a better bet. And ever so much sneakier.
Not that Facebook would actually need to employ steganography.
We know that Facebook uses artificial intelligence image recognition to understand both who is in any given photo and what is happening in that photo. Likewise, AI can identify the photo itself.Thus obviating any need for tricky invisible watermarking. Think Google Images reverse search employed in grand scale by the dark side. No need for steganography, then.
On the other hand
The irony here is that as far as metadata is concerned, Facebook is the least pernicious of the social media platforms. Facebook respects at least some of your copyright management metadata. As far as I know, they are the only social media platform to do so.
A trip to Facebook
In order to look at what Facebook does with metadata, I sent a picture on a round trip journey to and from the platform. I took a picture of an ibis and pasted onto it the entire metadata contents of the IPTC test image. Every single IPTC field was filled with a descriptive string.
This is what the picture looked like upon its return:
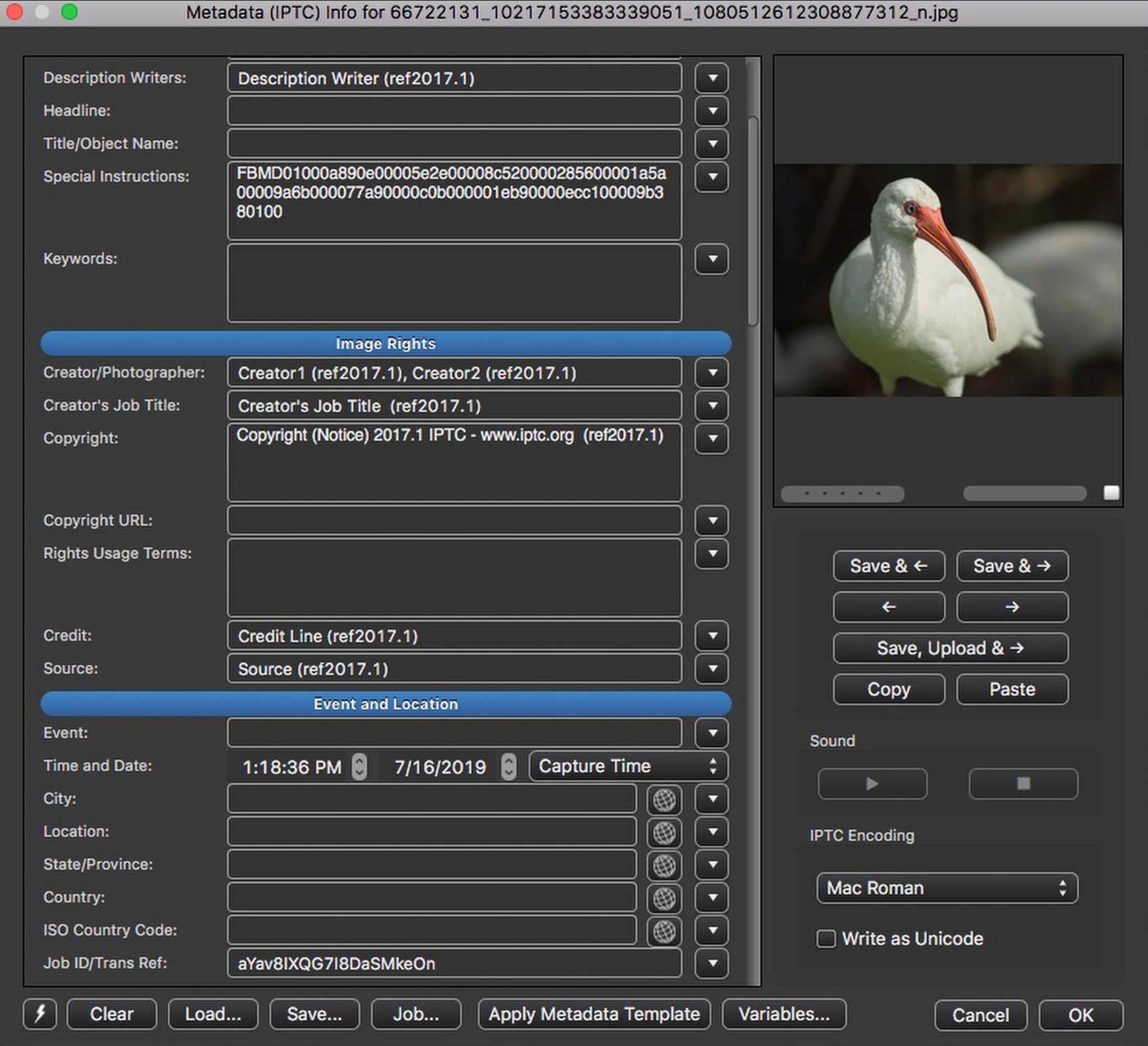
Here is all the IPTC metadata from the image in one place, as seen in ExifTool output. You’ll note that there are eight fields represented and that they are only recorded in the IIM data block. This last is clever from a bandwidth perspective. IIM data is very efficient indeed. XMP is much bulkier. Most all software can read IIM, so the lack of XMP doesn’t do much harm. Field names shown are the IIM names, which differ in Exiftool from the XMP ones.

My bird picture came back resampled from a hefty 5.8 MB to an emaciated 82 kilobytes. Facebook stripped the entire Exif data block, with its potentially troublesome geotagging data and bandwidth-wasting thumbnails. As they did with the XMP data block.
What was left
Remaining, in the IIM only, were eight IPTC fields. Six of those, Creator, Copyright, Creator’s Job Title, Credit, and weirdly, Source and Description Writer, were preserved as they were in the original. Two, Transmission Reference and Special Instructions, were overwritten with strings from Facebook. Content in all other fields was deleted.
The ICC profile was preserved, too. (One day, I’ll do a post about IIC profiles. Until then, it’s pretty safe not to worry about them.)
So, we should (relatively) commend Facebook for not destroying all the copyright management information in my picture.
They left enough intact that someone of benign intent downloading a photo should be able to figure out who owns it and contact that person for permission to use it. Assuming that the photographer bothered to write their name on their image in the first place, that is.
However, one might wonder why they destroyed any. One might also wonder if any of this is because of people of goodwill working at Facebook, or because they fear the European Union, where the courts aren’t too enthusiastic about the word “modify” in Facebook’s terms of use giving Facebook unlimited license to tamper with CMI. One as cynical as I am might wonder that, anyway.
Silly strings
Then there’s the matter of those strings they wrote. That’s where all the fun is.
Starting with the string in Transref.
Every content management system (they run websites, like this one) and digital asset management system (they store pictures) I’ve ever encountered assigns a unique ID number to each media file in its library. DAMs commonly write that unique ID to IPTC metadata, just in case humans might need it one day. That’s in addition, of course, to keeping it in the database, where it’s needed for the system to work. Usually, such a system writes the ID number to the Transref, because that’s the sort of thing that field was designed for.
(More or less. The original purpose of the Transref field was to hold the Transmission Reference, which is a string that identifies a wirephoto by a code indicating where it came from and an arbitrary sequence number. Nowadays we use it for job ticket numbers and all sorts of things.)
Facebook puts a very random-looking string of (in my sample) 20 alpha-numeric characters in the Transref. Twenty alpha-numeric characters could represent a number in the hundreds of nonillions. A nonillion is 1030. That’s a biiiig number. A trillion is a paltry 1012. The Transref field holds 32 characters in the IIM version. Even just using 20 of those, Facebook would have available plenty of unique numbers for each of its photos for the next little while.
(The IPTC’s own investigation of this matter revealed that the string in Transmission Reference does not change if the downloaded image is uploaded back to Facebook and re-downloaded. This further suggests that the Trasref string is indeed a unique ID. Remember that I’m speculating here. Facebook could do us all a service by simply telling us what they re doing.)
We’re all unique
While we are thinking about unique identifiers, we should consider that the filename on my sample image is 45 digits. Just numbers and underscores, but still, 45 figures makes a pretty good size number. It’s quite possible that the filename is also a unique identifier. While we really have no idea, we can surmise without being too silly that either or both of the filename and the string in the Transref might be a unique ID.
The string in Special Instructions is 99 characters long. We don’t know what it is, but it’s pretty clear it wouldn’t fit in Transmission Reference. If I remember correctly, in the IIM, Special Instructions can hold 256 characters.
Internet gadflies are twisting themselves into a conspiracy theory pretzel trying to parse what, if any, data might be being carried in the long Special instructions string. Come to think about it, that’s a pretty interesting question.
If the information is for Facebook’s use, why put it on the photo? Anything that uniquely identifies the photo would refer back to the appropriate place in the database, where we can assume all the relevant information about your entire life and being is stored. If the information is for our use, what it is and how to use it must have been in a memo that I missed.
Personally, given the many series of repeating and apparently place-holding zeros in that string, I’m betting that it does carry data. I would certainly be interested in knowing what kind, for whom, and generally, what the heck.
So, what do we know here?
The top line is that, of all the social media platforms, Facebook shows the most respect for the information you attach to your work. Is that the simple to say, and almost as simple to do, “respect embedded metadata”? No. I can’t think of an excuse for removing a picture’s caption, and whatever their reasoning for removing the remaining IIM fields was, we can safely criticize it for being pretty thin. Seriously, most of those fields are usually blank. If they hold values, it’s a safe assumption that the photographer put them there for a reason. I’m not terribly comfortable with removing the XMP data block in the long-term, but I’d be a hypocrite not to admit that I’ve advised clients to do the same thing in the here and now to same some bandwidth. (And at Facebook’s scale, the amount of storage space involved is not insignificant.)
Overall, we should commend Facebook for respecting enough metadata to allow Google Images “Image Credits” to work and to give an honest person a fair shot at figuring out who owns a given Facebook-sourced image.
On the matter of those mysterious strings, if I were to take a wild guess, I’d posit that they might be there in case the photo finds itself in some Facebook asset management system apart from the main CMS. Like, for instance if Facebook decided to avail themselves of another of those words in that terms of use license: “sub-licensable”. That would indeed be nefarious. That’s only my wild-ass guess, mind you. Facebook did not return an invitation to comment for this post.
I seriously doubt the strings are for surveillance. The etiquette of surveilling requires doing it with some degree of stealth. The government wouldn’t follow you around in marked police cars and a blimp. That would be rude. They would use black helicopters and shifty-looking guys in dark sunglasses. After all, politeness counts.
Is there a black van parked in front of your house? Have you decoded the 99-digit mystery number? Jump in the comments and say something we haven’t read on Twitter.
Dear Mr.Carel
I looking for same your topic, i have image but the some part metadata not existed because downloaded from Facebook, i want to know who first man uploaded it on faceback and take it by owns camera.
Please can you help me?
Kind regard
Seifeldin AlKhedir
saifeldinkhedir@gmail.com
If, IF, the person who uploaded the image to Facebook put his or her name and copyright information on the photo in the appropriate IPTC fields, that information should still be on the image when you download it. The Creator and Copyright fields are the only ones that survive a trip through Facebook. If the original uploader did not fill in those fields, you’re pretty much out of luck. All the Exif and all the other IPTC fields will have been removed. Your best chance at finding anything out about such a picture is to try to find the picture with reverse image search, either through Google or TinEye. Of course, Facebook knows exactly who uploaded it. But they won’t tell you 🙁
I had a bit of a databse issue on this site and I had to restore a backup, taking the site back a couple days. In the process I destroyed a comment from reader JB on this post. So, I’m rescontructing it from the notification email the server sedns out when you post a comment. Apologies to JB!
From JB:
This is slightly an “aside” comment because it pertains only to website links uploaded to Facebook, of which pictures are a subset.
Facebook has also been adding a parameter to HTTP GETs when users click on uploaded links. In other words, if I post a link to direct users to a photo gallery on my website, and another Facebook user clicks on it, a similar long encoded string is sent to my website along with their request. It looks like this:
GET /GALLERY/index.php?cat=10&fbclid=IwAR3DDgRkLMZicMTiaqrF19qdmsr4MIMfncNIQ3qDMd9MJUSdWJ-taXtfb4A
Everything after the “&” was added by FaceBook.
It seems to be unique per user, and it seems to be static. In other words, if the same user connects a month from now, the encoded “fbclid” string will be the same.
I don’t see how Facebook itself would benefit from doing this. Website owners might benefit from this because now they can determine how many hits came through the Facebook platform, and how many different IP addresses and web bowzers they have. If the website owner is a Facebook partner, then there could be some business collaboration based on that number. But it seems benign compared to Google, Akamai, and all the other H.Pylori Web Monsters out there.
Some web developers complain about the added parameter because sometimes they write code that depends on the exact format of the URL passed to the server.
Indeed. It seems backwards to me, too.
Whatever it is, Facebook is doing it openly. Which is either transparency or arrogance. Who knows….
Looks like Facebook is stripping everything now. I’ve entered several fields into the metadata of .jpg files, and everything is being stripped during the upload. 🙁
Yes. Sadly. Some people over on the IPTC list have noticed something going on as well. Not only does Facebook screw over content creators but their behavior just gets worse. What do you bet they refuse to communicate with anybody – stakeholders or journalists – about it? If I turn out to be too cynical about this, I’ll post back to gladly eat crow.
Hi Carl,
Thank you for your hard work. I’ve been researching metadata in images as a path for malware intrusion.
This is one article: https://null-byte.wonderhowto.com/how-to/hacking-macos-hide-payloads-inside-photo-metadata-0196815/
Like many, I’ve written my own image uploader and resizer and wanted to ensure that I’m not going to get something I didn’t ask for.
So far, it appears that PHP’s GD library will ‘clean slate’ an image of much of the metadata. This means that the process is to upload the image, make a copy of it, delete the original and then work on the copy.
Is it possible that Facebook is removing metadata for security reasons?
Ah! It’s a feature, not a bug! Yes, GD strips metadata. In the midst of a raging epidemic of copyright infringement and mis/disinformation, this presents a significant problem for society, given that GD is used on a majority (granted, an ever-shrinking majority) of websites. When I last spoke with GD’s maintainer, he was aware of the issue and had roadmapped metadata support for a future release – presumably user-configurable, or defeatable for those who have special needs.
That said, there is metadata and metadata. Programs that “strip” don’t necessarily strip every last bit of metadata. Too heavy a hand and the file won’t even open. That would be something to bear in mind in your endeavors. Checking with Exiftool or a hex editor might be in order to see what’s left over after a given program does its stripping.
As I understand it, at this point, metadata payloads are only a supply vector into systems that are already compromised. So, not too frightening just yet.
Of course, destroying the very data we mean to protect is a pretty blunt way to protect it. In short order I expect anti-virus/firewall programs to be able to inspect metadata on image files and detect potential threats. There aren’t that many places in a photo header to hide nasty payloads. This seems to me to be a door that’s only briefly open – until security measures slam it shut and hackers move on to their next brainstorm.
Facebook makes revenue from trafficking in stolen content and misinformation. From its perspective, the term “security” may have an entirely different meaning than it might to the victims of those behaviors.
may be Facebook is using these data to track
1. the original uploader of the image
2. to save space, if somebody download the image and upload by other users. they can only use the one copy
Nobody knows, of course. They can certainly accomplish both of those things in their database without writing anything to the photos. And nobody – that I know of anyway – knows of that string ever being used for anything by anybody. In a halfway normal world, we could just ask. Well, I did ask, actually. They didn’t/don’t respond. Is it a big conspiracy or simply silliness?
I can’t help but note the irony that, if Facebook intended to use that string to determine if an image found in the wild had been published on Facebook, they would run slam into the fact that other social media outfits do just what they do – strip the metadata(!)